
前言
群里有一位朋友提出一个问题,说他需要一个在线批量orc识别图片文字,并且保存为文本。因为他手里有几百张照片,但是正常的工具只能一次处理一张,很麻烦。
其实图片识别文字的网站网上一搜到处都是,微信也自己图片识别。但是,这位朋友的需求是批量生成,这种要求都是带有商用性质的,批量生成内容必然带有一定服务器资源的消耗,线上服务是不会给你完全免费的。从逻辑上,你要在线上批量图片识别文字,你能找到免费的网站——估计是那个开发者脑子有问题,这批量任务相当于是网络攻击,直接可以把它网站给干废了···
其实在生活中,orc图片识别文字的运用非常广泛,日常的监控、扫一扫中都有运用到这项技术。而这项技术已经不算啥新技术黑科技了,因此也有很多开源的项目。

Umi-OCR
【Umi-OCR】是GitHub上的开源项目,它是一个支持离线、批量文字OCR识别的小工具。软件基于百度的飞浆——PaddleOCR的离线OCR模块开发,根据介绍可以训练模型,支持修改PaddleOCR参数,添加不同的语言模型。一款特别好用的免费批量文字识别软件。
其实就是百度飞浆把图片识别文字的技术开源了,因此开发者可以利用这个开源的技术再开发各种工具。
Umi-OCR的项目地址:https://github.com/hiroi-sora/Umi-OCR
读者也可以通过公众号回复:文字识别,获取国内直连下载地址(包括多语言文字识别库)。
注意事项
此工具只支持win10 64位以上的版本。
CPU必须具有AVX指令集。(不懂自己查一下,2012年之后的CPU一般都支持)
功能丰富
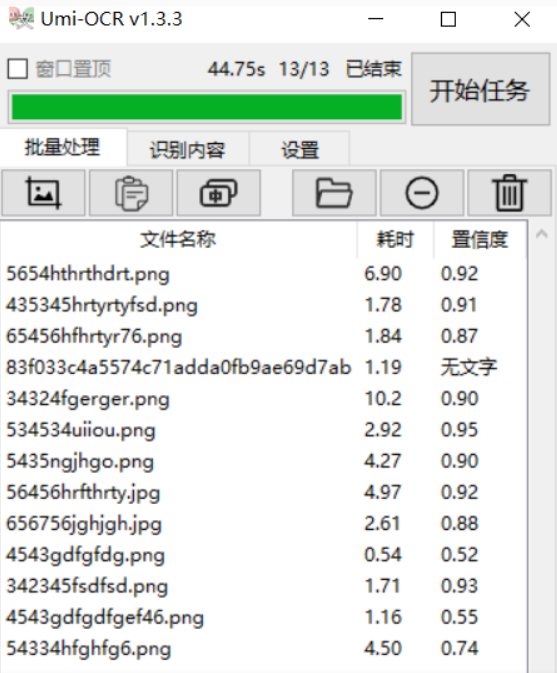
这个软件的功能还是比较丰富的,可以实现不少需求。日常使用的时候,你可以直接屏幕截图,直接将屏幕上的图片截取识别文字信息。
可以批量导入图片,导出为 txt / md / jsonl 多种格式文件。处理过程中会显示耗时、以及置信度。如果你本身图片中文字的像素不高或者比较潦草,自然识别可信度会下降。有些图片里的字人都看不出来写的啥,别说AI了···
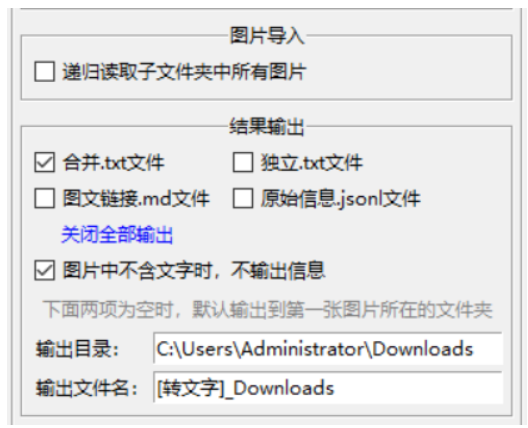
默认的引擎是识别为中英文文字识别,也可额外导入繁中,英,日,韩,俄,德,法 识别库。
导入的方法也很简单,下载安装包里也写了教程,这里不再复述。
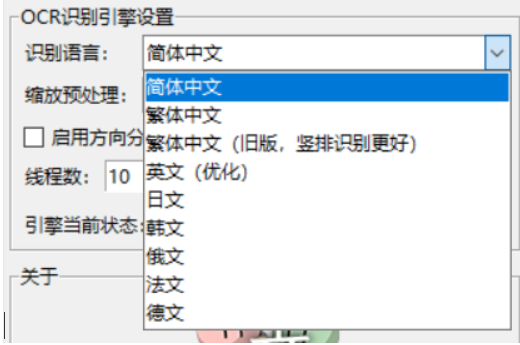
可以设置区域编辑器,类似含水印的视频截图、含有UI/按钮的游戏截图等,往往只需要提取字幕区域的文本,而避免提取到水印和UI文本。
其实就是一批照片可能有水印之类的东西,但是你可以屏蔽掉这部分的识别。或者只选择自己需要的区域进行识别。这个功能还是比较有用的。
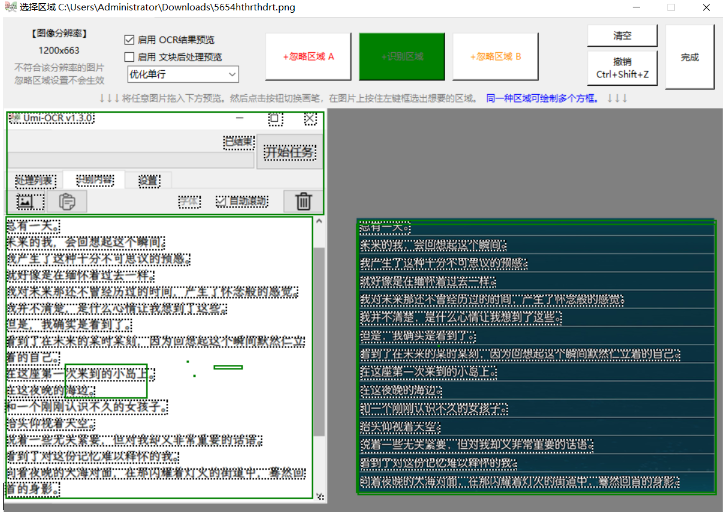
并且输出的字体、字号都可以调整。文字顺序是横竖也都可以进行设置。
评论 (0)